
矢量数据库的兴起
近年来,生成式人工智能的快速发展,许多公司都争先恐后地将人工智能融入到自己的业务中。最常见的方法之一是构建人工智能系统来回答有关可在文档数据库中找到的信息的问题。此类问题的大多数解决方案都基于一项关键技术:检索增强生成(RAG)。
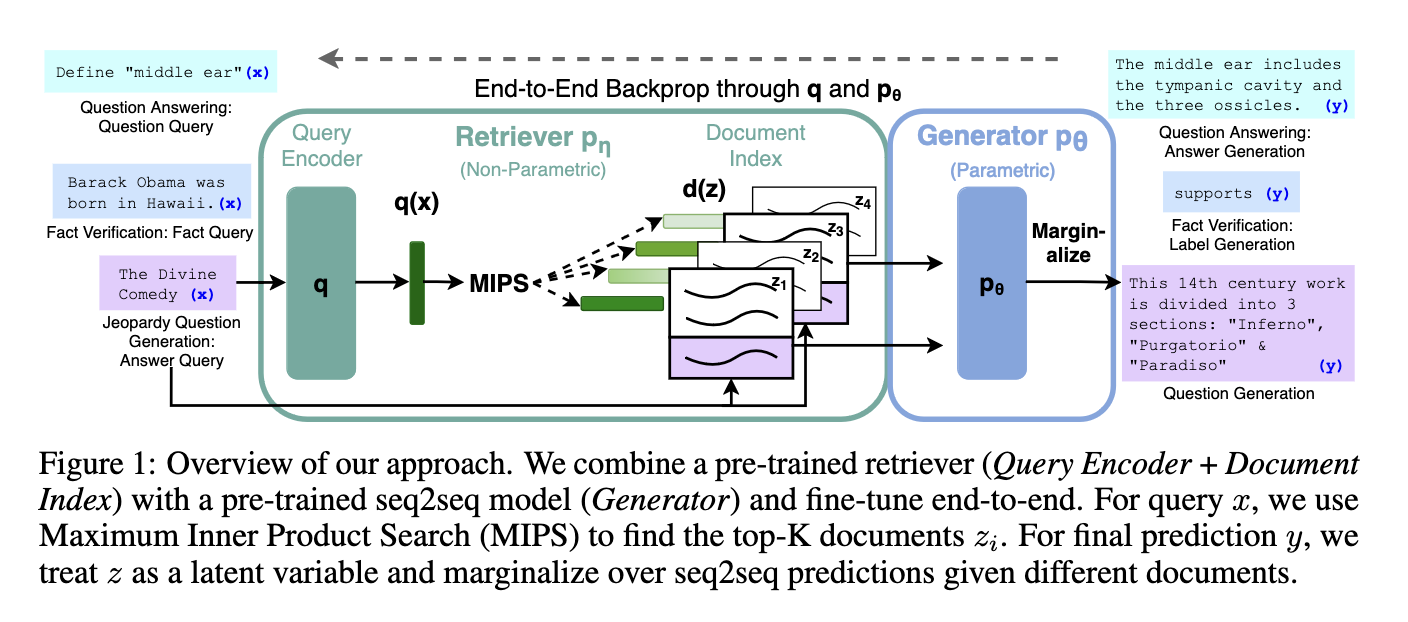
这就是许多人现在所做的,作为开始使用人工智能的一种廉价且简单的方法:在数据库中存储大量文档,让人工智能检索与给定输入最相关的文档,然后生成对输入的响应由检索到的文档通知。
这些 RAG 系统通过使用“嵌入”(嵌入模型生成的文档的向量表示)来确定文档相关性。这些嵌入应该表示一些相似性的概念,因此与搜索相关的文档在嵌入空间中将具有较高的向量相似性。
RAG的流行导致了矢量数据库的兴起,这是一种新型数据库,旨在存储和搜索大量嵌入;数亿 美元 的 资金已经发放给那些声称通过简化嵌入搜索来促进 RAG 的初创公司。RAG 的有效性是许多新应用程序将文本转换为向量并将其存储在这些向量数据库中的原因。
嵌入很难阅读
那么文本嵌入中到底存储了什么?除了语义相似性的要求之外,对于给定文本输入必须分配什么嵌入没有任何限制。嵌入向量中的数字可以是任何数字,并且根据它们的初始化而变化。我们可以解释一段文本与其他文本的相似之处,但无法理解嵌入的各个数字。

现在假设您是一名软件工程师,正在为您的公司构建 RAG 系统。您决定将矢量存储在矢量数据库中。您会注意到,在向量数据库中,存储的是嵌入向量,而不是文本数据本身。数据库中充满了一行又一行看似随机的数字,这些数字代表文本数据,但根本“看不到”任何文本数据。
您知道该文本对应于受贵公司隐私政策保护的客户文档。但是,您实际上并没有在任何时候将文本发送到外部,您只发送向量,它们看起来像随机数。
如果有人侵入数据库并访问您所有的文本嵌入向量怎么办?这会很糟糕吗?或者,如果服务提供商想将您的数据出售给广告商,他们可以吗?这两种情况都涉及能够获取嵌入向量并以某种方式将它们反转回文本。
从文本到嵌入…回到文本
从嵌入中恢复文本的问题正是我们在论文《文本嵌入与文本一样显示》 (EMNLP 2023)中解决的场景。嵌入向量是信息存储和通信的安全格式吗?简而言之:输入文本可以从输出嵌入中恢复吗?
在深入研究解决方案之前,让我们先思考一下这个问题。文本嵌入是神经网络的输出,是由应用于输入数据的非线性函数运算连接起来的矩阵乘法序列。在传统的文本处理神经网络中,一个字符串输入被分割成多个标记向量,这些标记向量反复进行非线性函数运算。在模型的输出层,标记被平均为单个嵌入向量。
信号处理界的一条格言(称为数据处理不等式)告诉我们,函数不能向输入添加信息,它们只能维持或减少可用信息量。尽管传统观点告诉我们,神经网络的更深层次正在构建更高阶的表示,但它们并没有添加任何输入端未输入的有关世界的信息。
此外,非线性层肯定会破坏一些信息。现代神经网络中普遍存在的非线性层是“ReLU”函数,它只是将所有负输入设置为零。在典型文本嵌入模型的多层中应用 ReLU 后,不可能保留输入中的所有信息。
其他情况下的反转
计算机视觉社区也提出了有关信息内容的类似问题。一些结果表明,图像模型的深度表示(本质上是嵌入)可用于以一定程度的保真度恢复输入图像。早期结果(Dosovitskiy,2016)表明可以从深度卷积神经网络(CNN)的特征输出中恢复图像。考虑到 CNN 的高级特征表示,他们可以将其反转以生成原始输入图像的模糊但相似的版本。

自 2016 年以来,人们对图像嵌入反演过程进行了改进:已经开发出能够以更高的精度进行反演的 模型,并且已被证明可以在更多设置下工作。令人惊讶的是,一些工作表明图像可以从 ImageNet 分类器的输出(1000 个类别概率)中反转。
vec2text 之旅
如果反转可以用于图像表示,那么为什么它不能用于文本呢?让我们考虑一个恢复文本嵌入的玩具问题。对于我们的玩具设置,我们将文本输入限制为 32 个标记(大约 25 个单词,一个长度合适的句子),并将它们全部嵌入到 768 个浮点数的向量中。在 32 位精度下,这些嵌入为 32 * 768 = 24,576 位或大约 3 KB。
许多位代表很少的字。您认为我们可以在这个场景中完美地重建文本吗?
首先,我们需要定义一个衡量良好程度的标准,以了解我们完成任务的情况。一个明显的指标是我们在反演后获得准确输入的频率。先前的反演方法在这种精确匹配上没有取得任何成功,因此这是一个相当雄心勃勃的测量。因此,也许我们想从平滑的测量开始,测量倒置文本与输入的相似程度。为此,我们将使用 BLEU 分数,您可以将其视为反转文本与输入的接近程度的百分比。
定义了成功指标后,让我们继续提出一种使用所述指标进行评估的方法。对于第一种方法,我们可以将反演视为传统的机器学习问题,并以我们知道的最佳方式解决它:通过收集嵌入文本对的大型数据集,并训练模型以输出给定嵌入的文本:输入。
这就是我们所做的。我们构建了一个转换器,将嵌入作为输入,并使用传统语言建模对输出文本进行训练。第一种方法为我们提供了 BLEU 分数约为 30/100 的模型。实际上,模型可以猜测输入文本的主题,并得到一些单词,但它会丢失它们的顺序,并且经常弄错大部分单词。准确的比赛分数接近于零。事实证明,要求一个模型在一次前向传递中反转另一个模型的输出是相当困难的(其他复杂的文本生成任务也是如此,例如以完美的十四行诗形式生成文本或满足多个属性)。
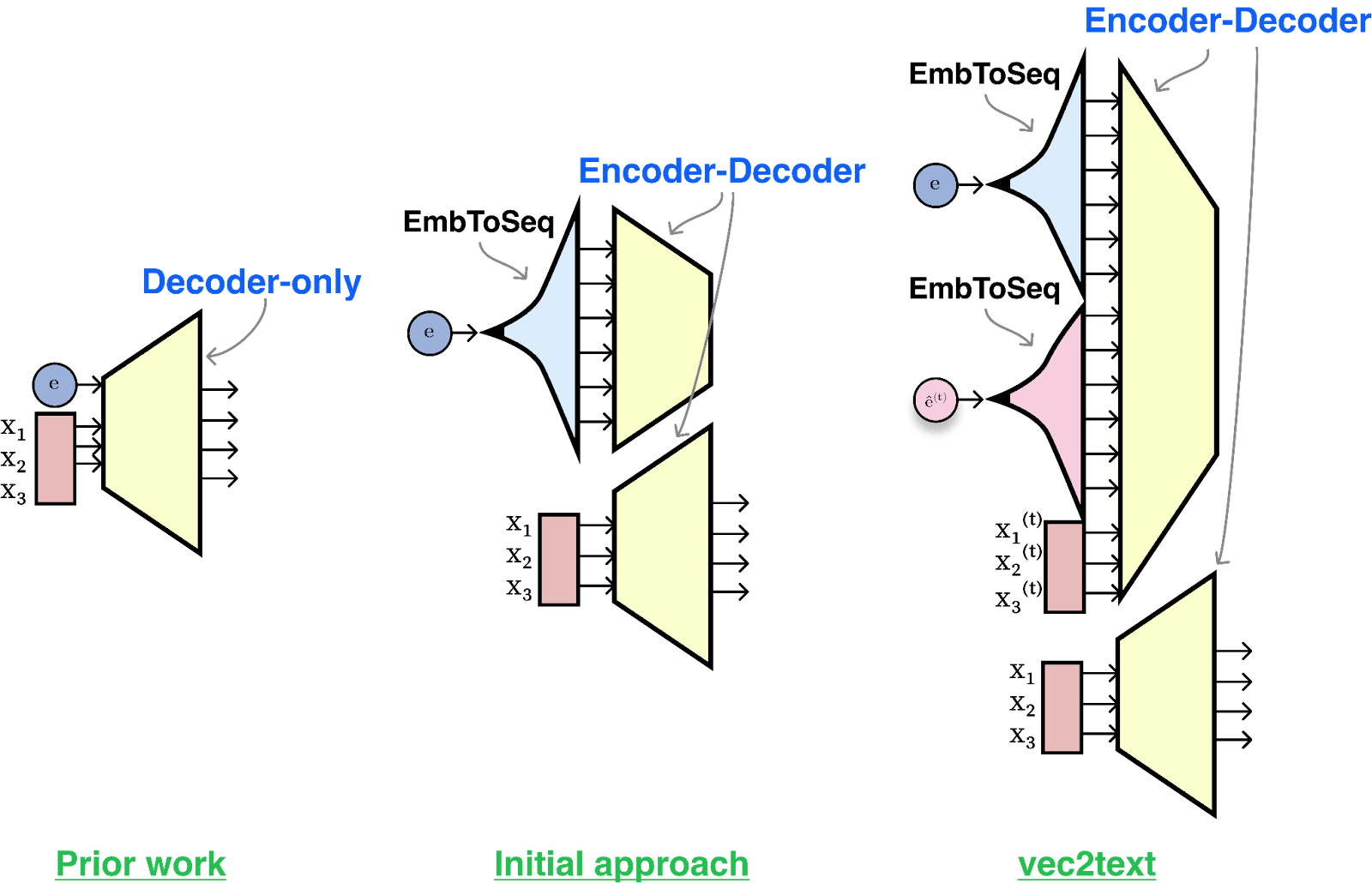
在训练我们的初始模型后,我们注意到一些有趣的事情。衡量模型输出质量的另一种方法是重新嵌入生成的文本(我们称之为“假设”)并测量该嵌入与真实嵌入的相似度。当我们对模型的各代进行此操作时,我们看到非常高的余弦相似度 – 大约 0.97。这意味着我们能够生成嵌入空间接近但与真实文本不同的文本。
(顺便说一句:如果情况并非如此怎么办?也就是说,如果嵌入为我们错误的假设分配了与原始序列相同的嵌入,会怎么样。我们的嵌入器将是有损的,将多个输入映射到相同的输出。如果这是如果是这种情况,那么我们的问题将毫无希望,我们将无法区分多个可能序列中的哪一个产生了它。实际上,我们在实验中从未观察到此类碰撞。)
假设对真实情况具有不同的嵌入这一观察激发了一种类似优化的嵌入反演方法。给定一个真实的嵌入(我们想要去的地方),以及当前的假设文本及其嵌入(我们现在所处的位置),我们可以训练一个校正器模型,该模型经过训练可以输出比真实情况更接近的东西。假设。
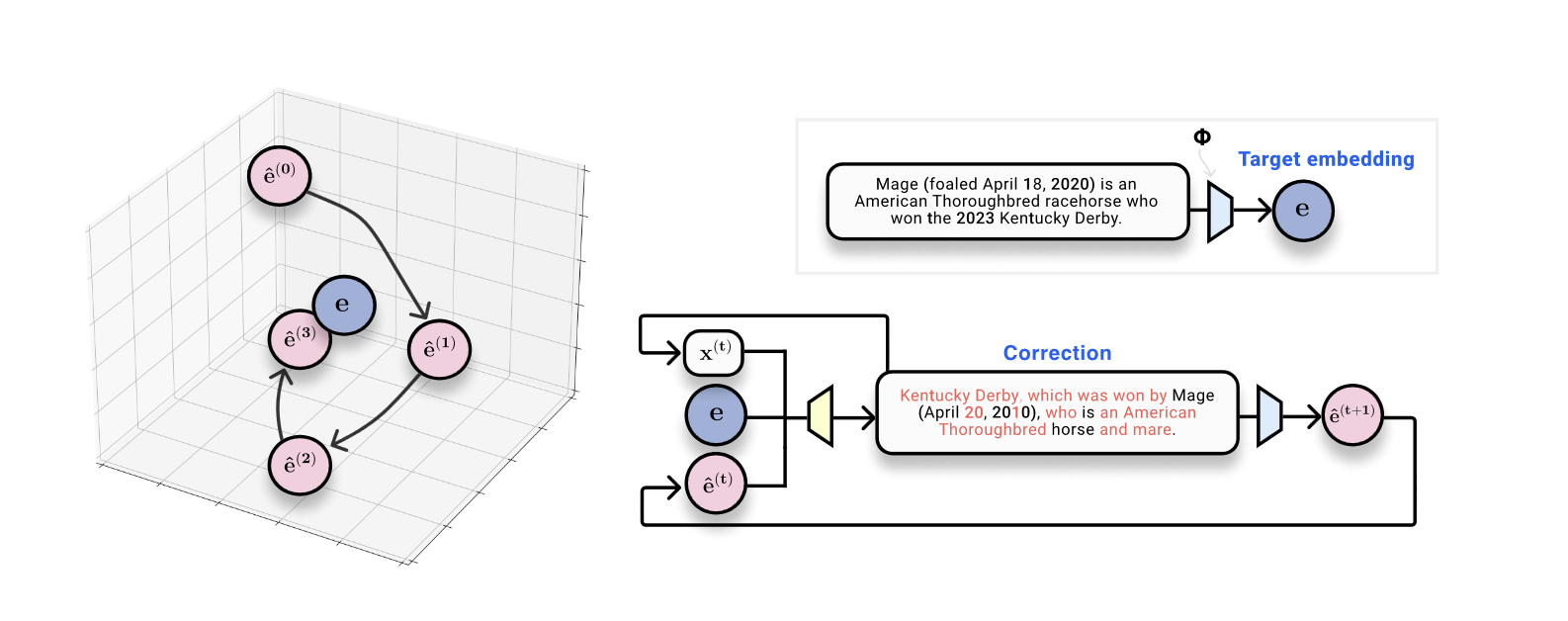
现在我们的目标很明确:我们希望构建一个系统,可以采用真实嵌入、假设文本序列以及嵌入空间中的假设位置,并预测真实文本序列。我们认为这是一种“学习优化”,我们采取步骤以离散序列的形式嵌入空间。这是我们称为 vec2text 的方法的本质。
在完成一些细节并训练模型后,这个过程非常有效!一次前向传递校正将 BLEU 分数从 30 提高到 50。该模型的一个好处是它可以自然地递归查询。给定当前文本及其嵌入,我们可以运行此优化的许多步骤,迭代生成假设,重新嵌入它们,并将它们作为模型的输入反馈回来。通过 50 个步骤和一些技巧,我们可以准确地恢复 92% 的 32 个标记序列,并获得 97 的 BLEU 分数!(一般来说,BLEU 得分达到 97 分意味着我们几乎完美地重建了每个句子,也许有些标点符号放错了地方。)
扩展和未来的工作
文本嵌入可以完美反转的事实引发了许多后续问题。其一,文本嵌入向量包含固定数量的比特;必须存在一定的序列长度,达到该长度信息就无法再完美地存储在该向量中。尽管我们可以恢复大多数长度为 32 的文本,但某些嵌入模型可以嵌入多达数千个标记的文档。我们将分析文本长度、嵌入大小和嵌入可逆性之间的关系留给未来的工作。
另一个悬而未决的问题是如何构建可以防御反转的系统。是否有可能创建能够成功嵌入文本的模型,使得嵌入在混淆创建它们的文本的同时仍然有用?
最后,我们很高兴看到我们的方法如何应用于其他模式。vec2text(嵌入空间中的一种迭代优化)背后的主要思想不使用任何特定于文本的技巧。这是一种迭代恢复任何固定输入中包含的信息(给定对模型的黑盒访问)的方法。这些想法如何应用于其他模式的反转嵌入以及比嵌入反转更通用的方法还有待观察。
要使用我们的模型来反转文本嵌入,或者开始自己运行嵌入反转实验,请查看我们的 Github 存储库:
https: //github.com/jxmorris12/vec2text
参考
用卷积网络反转视觉表示(2015),https://arxiv.org/abs/1506.02753
通过判别训练分类器的前馈反转了解不变性(2021),https://proceedings.mlr.press/v139/teterwak21a/teterwak21a.pdf
文本嵌入(几乎)与文本一样多(2023),https://arxiv.org/abs/2310.06816
语言模型反转(2024),https://arxiv.org/abs/2311.13647